
How ChatGPT Gets Information: The Complete 2026 Guide to AI Knowledge Sources
Quick Answer
How ChatGPT Gets Information: The Complete 2026 Guide to AI Knowledge Sources: choose one monetization path, publish intent-matched content, and optimize offers based on weekly conversion data.
ChatGPT doesn’t “know” things the way you do. It predicts what comes next based on patterns from billions of text samples. Understanding exactly where ChatGPT pulls its information—and where it falls short—is the difference between using AI effectively and getting burned by hallucinations.
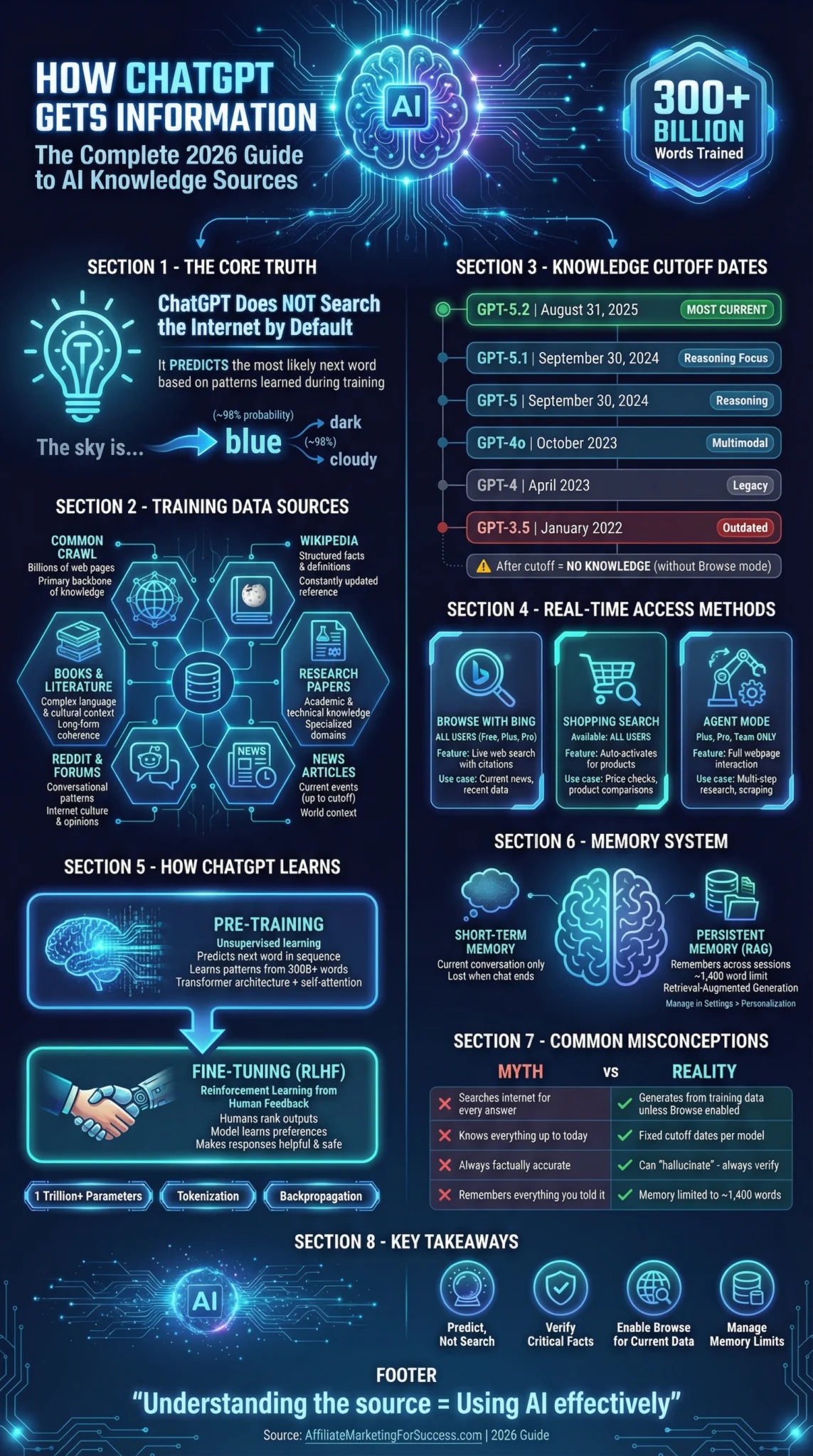
Here’s the truth nobody tells you: ChatGPT doesn’t actually “search” for information when you ask it something. It generates responses by predicting the most statistically likely next word based on patterns learned during training. The data it learned from? A cocktail of 300+ billion words from the internet, books, and research papers—with a hard cutoff date where its knowledge simply stops.
⚡
Key Takeaways
- Training Data: ChatGPT learns from Common Crawl web data, Wikipedia, books, research papers, news articles, and online forums like Reddit
- Knowledge Cutoff: GPT-5.2 (latest) has data through August 31, 2026; GPT-4o stops at October 2023
- Real-Time Access: Browse with Bing, Shopping Search, and Agent Mode provide live web access
- Memory System: Uses RAG (Retrieval-Augmented Generation) to remember details across conversations
- Training Method: Transformer neural networks + Reinforcement Learning with Human Feedback (RLHF)

📚 Where ChatGPT’s Training Data Actually Comes From
OpenAI trained ChatGPT on a mixture of licensed data, human trainer-created content, and publicly available text from the web. The exact proportions remain proprietary, but the primary sources are well-documented.
🌐
Common Crawl
Primary Data Source
Contains billions of web pages collected through automated web scraping. This massive repository provides diverse content including news, blogs, forums, and general websites—forming the backbone of ChatGPT’s broad knowledge base.
📖
Books & Literature
Deep Knowledge
Extensive collections of published books provide complex language structures, cultural contexts, and in-depth subject matter. This enhances ChatGPT’s ability to handle nuanced topics and produce coherent long-form responses.
📰
Wikipedia
Structured Knowledge
Provides constantly updated, structured factual information. Wikipedia’s encyclopedic format ensures ChatGPT has access to verified facts, definitions, and historical data across countless topics.
🔬
Research Papers
Academic Insights
Scientific papers and technical documentation help ChatGPT understand specialized domains, formal writing styles, and peer-reviewed findings. This is why it can discuss complex scientific concepts with reasonable accuracy.
💬
Online Forums & Reddit
Conversational Patterns
Discussion boards and social platforms teach ChatGPT conversational language patterns, internet culture, and user-generated insights. A 2026 Semrush study revealed Reddit is a significant source for ChatGPT’s factual responses.
📺
News Articles
Current Events
News websites provide information about events, current affairs, and timely topics up to the knowledge cutoff date. This helps ChatGPT discuss historical events and provide context for world affairs.
For affiliate marketers, understanding these sources matters because ChatGPT’s responses about products, trends, and strategies are only as good as the data it was trained on. If you’re asking about how chatbots can make you money, you’ll get solid foundational advice—but real-time market conditions require live data access.
📅 ChatGPT Knowledge Cutoff Dates: What Each Model Knows
Every ChatGPT model has a “knowledge cutoff”—the date after which it has no training data. This is critical to understand because ChatGPT cannot tell you about events, products, or changes that happened after its cutoff without using real-time search features.
⚠️ Critical for Affiliate Marketers: If you’re researching Google ranking factors or current SEO strategies, always verify ChatGPT’s responses against real-time sources. Algorithm updates, policy changes, and market shifts happen constantly—and your model’s cutoff determines whether it knows about them.
🔍 How ChatGPT Accesses Real-Time Information
As of 2026, ChatGPT offers three distinct methods to access current information beyond its training data. Each serves different use cases and is available based on your subscription tier.
🌐
Browse with Bing
The default web search tool available to all users (Free, Plus, Pro, Team). Retrieves fresh web results from indexed public pages with numbered citations.
- Summarizes content with source links
- Works across desktop and mobile
- Powered by Bing’s search infrastructure
- Ignores paywalled content
🛒
Shopping Search
Automatically activates for product-related queries. Available to all users including free tier.
- Quick product comparisons
- Price and availability checks
- Best for purchase decisions
- No direct site visits required
🤖
Agent Mode
Advanced feature for Plus, Pro, and Team subscribers. Enables full-page interaction and automation.
- Multi-step page navigation
- Screenshots and clickable paths
- Structured research workflows
- Site scraping capabilities
When you’re conducting keyword research or analyzing competitor content, the Browse feature can pull current SERP data—but always cross-reference with dedicated SEO tools for accuracy.
🧠 How ChatGPT Actually Learns: The Training Process
Understanding the training process reveals why ChatGPT responds the way it does—and where its limitations come from. The process involves two critical phases.
⚙️ Two-Phase Training Architecture
1
Pre-Training (Unsupervised)
The model is fed massive amounts of unlabeled text data. It learns by predicting what word comes next in a sequence, identifying statistical patterns in language. This phase uses the Transformer architecture with self-attention mechanisms to understand context and relationships between words.
2
Fine-Tuning (RLHF)
Human trainers evaluate and rank model outputs. Through Reinforcement Learning with Human Feedback, the model learns to produce responses that align with human preferences—making outputs more helpful, harmless, and honest.
🔑 Key Technical Components:
- Transformer Architecture: Uses self-attention to weigh the importance of each word relative to all others
- Tokenization: Text is broken into tokens (words or word-parts) assigned numerical values
- Backpropagation: Adjusts neural network weights based on prediction errors
- Parameters: GPT-4 has over 1 trillion parameters (weights and biases) that store learned patterns
This is why prompt engineering matters so much. You’re essentially giving the model the right statistical context to generate useful outputs. Better prompts = better pattern matching = better results.
💾 How ChatGPT’s Memory System Works
ChatGPT has evolved beyond single-conversation interactions. The memory system now allows continuity across sessions—but understanding its limitations prevents frustration.
⏱️ Short-Term Memory
Retains context only during the current conversation. ChatGPT tracks the flow of discussion and references previously mentioned topics within the same session.
Limitation: Once the conversation ends or refreshes, this information is lost. Each new chat starts fresh unless persistent memory is enabled.
🗄️ Persistent Memory (RAG)
Uses Retrieval-Augmented Generation to store and recall information across sessions. Indexes relevant parts of your conversations into a searchable database.
Capacity: Approximately 1,200-1,400 words total. When full, new memories won’t save until you delete old ones via Settings > Personalization > Memory.
💡 How RAG Works Behind the Scenes:
When you send a message, ChatGPT performs a semantic search within its memory database to retrieve relevant past discussions—your goals, interests, or frequently asked questions. This information is incorporated into the prompt, allowing continuity over time without requiring you to repeat yourself.
🎯 Practical Applications for Affiliate Marketers
Now that you understand how ChatGPT gets information, here’s how to leverage this knowledge for your affiliate marketing business.
✍️
Content Creation
ChatGPT excels at generating drafts, outlines, and variations. Its training on diverse content makes it versatile for different niches.
✓ Best for: Blog outlines, email sequences, social captions
🔎
Research & Analysis
Use Browse mode for current data. Without it, responses are limited to the knowledge cutoff date.
⚠️ Warning: Always verify statistics and claims independently
📊
Strategy Development
Leverage its training on business content for frameworks, competitive analysis templates, and marketing strategies.
💡 Pro tip: Use memory to store your niche details for contextual responses
For a deeper dive into using AI effectively, check out our guide on learning prompt engineering—it’s the skill that separates mediocre AI outputs from genuinely useful results.
🚫 Common Misconceptions About ChatGPT’s Knowledge
✗
“ChatGPT searches the internet for every answer”
Reality: Without Browse mode enabled, ChatGPT generates responses purely from its training data. It doesn’t fetch information in real-time by default—it predicts text based on learned patterns.
✗
“ChatGPT knows everything up to today”
Reality: Each model has a fixed knowledge cutoff. GPT-5.2’s cutoff is August 2026; GPT-4o stops at October 2023. Events after these dates require Browse mode or won’t be known at all.
✗
“ChatGPT’s responses are always factually accurate”
Reality: ChatGPT can “hallucinate”—generating plausible-sounding but entirely false information. It’s designed to predict likely text, not verify truth. Always fact-check critical information.
✗
“ChatGPT remembers everything you’ve ever told it”
Reality: Memory is limited to ~1,400 words and must be explicitly enabled. Without persistent memory turned on, each conversation starts completely fresh with no recall of previous sessions.
❓ Frequently Asked Questions
📚 Sources & References
Official resources and additional reading
- Introducing ChatGPT Search – OpenAI
Official announcement of ChatGPT’s real-time search capabilities - ChatGPT Capabilities Overview – OpenAI Help Center
Complete guide to ChatGPT features and functionality - Knowledge Cutoff Dates in Large Language Models – Allmo.ai
Comprehensive database of LLM knowledge cutoff dates - What is GPT AI? – Amazon Web Services
Technical explanation of GPT architecture and training - What is GPT and How Does it Work? – Google Cloud
In-depth overview of transformer models and self-attention mechanisms
Written By
Alexios Papaioannou
Founder of Affiliate Marketing For Success. Specializing in AI-powered marketing strategies, SEO optimization, and helping affiliate marketers leverage cutting-edge tools to grow their businesses.
Last Updated: January 13, 2026
Our Editorial Standards
- No paid placements or rankings
- We never claim to test products we haven’t personally evaluated
- All affiliate relationships are clearly disclosed
- Facts are verified against official sources
📚 Related Articles on AFS
Keep learning with these hand-picked guides:
I’m Alexios Papaioannou, an experienced affiliate marketer and content creator. With a decade of expertise, I excel in crafting engaging blog posts to boost your brand. My love for running fuels my creativity. Let’s create exceptional content together!





